Distance-structure fidelity,
verified in the open.
Can a claim about precursor monitoring be made reproducible?
Using 768-dimensional synthetic data with known ground-truth geometry, we quantitatively compared how faithfully seven dimensionality-reduction methods (PCA / Isomap / t-SNE / UMAP / PyMDE / PCC / toorPIA) carry high-dimensional distance structure into 2D, using distance-band Shepard ρ as a common metric. The code, the hypotheses, and every method's output coordinates are published on GitHub — every number can be recomputed offline by anyone.
7 methods
compared under identical conditions
5.2–6.4×
separation of unseen anomalies (vs. normal-region radius)
10/10
anomalies attributed to their source
This benchmark is created and maintained by the vendor of toorPIA. Precisely because of that, it was designed so that its conclusions do not depend on our judgment.
- 01Metrics are computed independently of every method, exactly, on all pairwise distances
- 02Hypotheses are documented and committed before the results are produced
- 03Every method's output coordinates are published — all numbers are third-party recomputable offline
- 04No winner is claimed when confidence intervals overlap
The repository is published under the MIT License.
Build the map from normal data only.
Then add the unseen anomalies.
A reference map is built from data containing no anomalies at all, and unseen anomalies are then added to it one by one (addplot). This is not an artificial laboratory setup — it is the monitoring operation itself. Each anomaly shares the measured features of a normal cluster while shifting along new dimensions in which the normal data never varies.
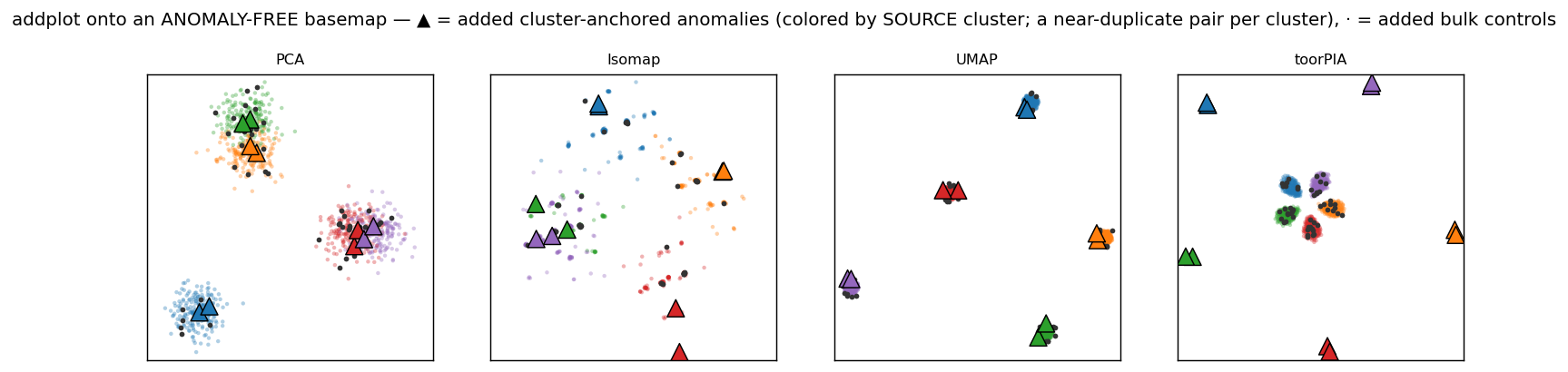
▲ = added anomalies (colored by source cluster). In PCA, Isomap, and UMAP the anomalies sink into the normal clusters; in toorPIA every anomaly lands clearly outside the normal region, pointing toward the cluster it originated from.
t-SNE / PyMDE / PCC
These methods have no out-of-sample transform — no way to place a new point on an existing map. They cannot perform this monitoring operation at all.
PCA / Isomap / UMAP
They can place the anomalies, but at a median distance of only 0.96–1.34× the normal-region radius — the anomalies are buried inside the normal data, giving detection nothing to work with.
toorPIA
Every anomaly is separated to 5.2–6.4× the normal-region radius (identical across seeds), and its direction points at the source cluster (attribution 10/10, angular error 0.6°). The only method that answers both “something is wrong” and “where it comes from.”
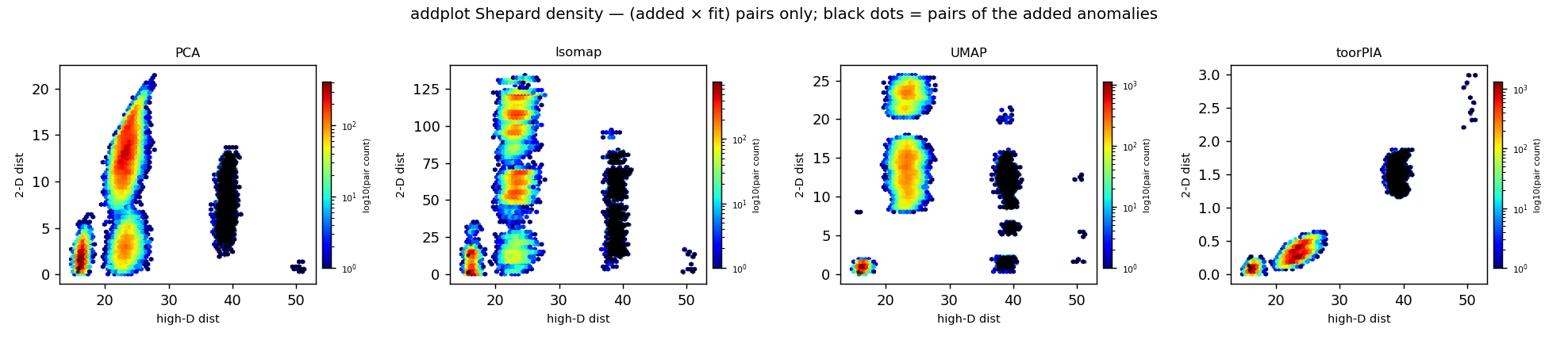
High-dimensional distance (x) vs. 2D distance (y) for added × reference pairs. Only toorPIA keeps the relation monotonic, with the anomaly pairs (black) separated at the far end.
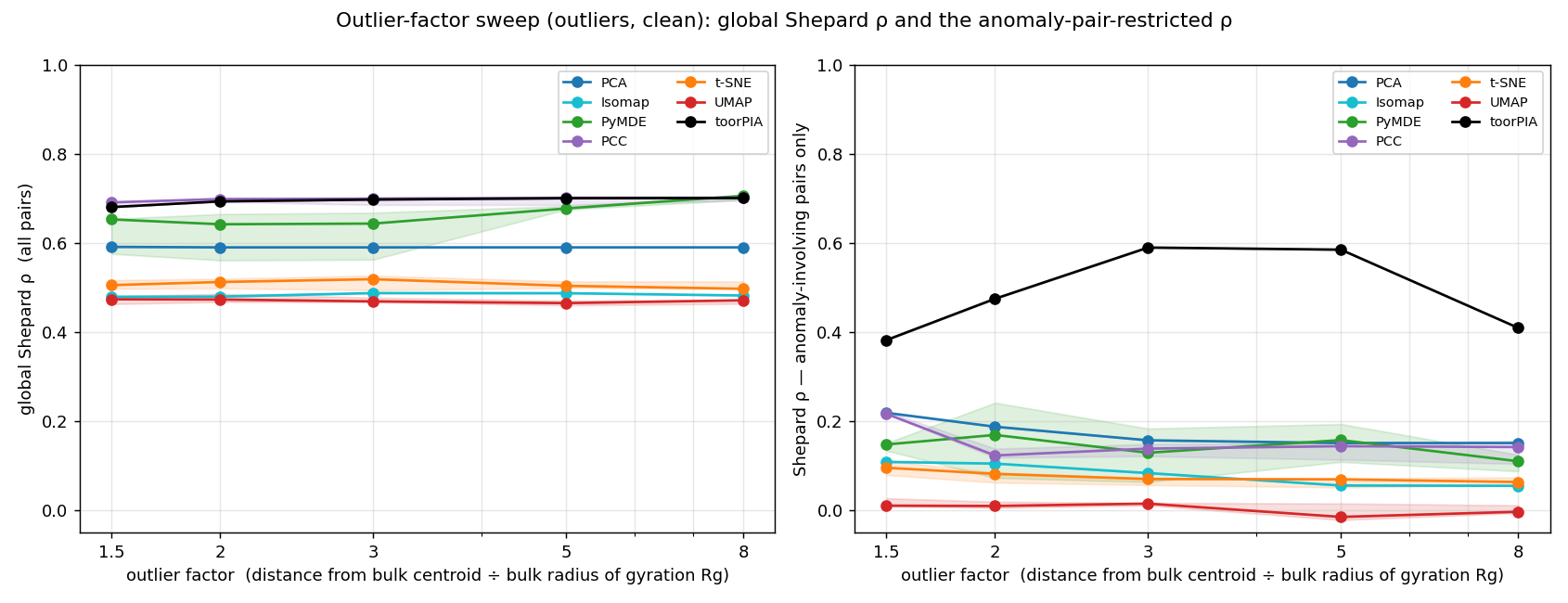
Sweeping the anomaly strength (1.5–8× the normal-region radius). On ρ restricted to anomaly-involving pairs (right), toorPIA (black) leads by a wide margin across the whole range.
A monitoring baseline that
doesn't move when you rebuild it
t-SNE and UMAP are stochastic: the same data produces a different layout on every run. toorPIA is fully deterministic — results are identical across seeds. In the out-of-sample test above, the separation distances of the anomalies matched exactly from seed to seed, with zero run-to-run wobble.
Stochastic methods (t-SNE / UMAP, etc.)
The layout changes on every run
Normal regions and thresholds drift with each retraining, forcing the monitoring baseline to be re-tuned.
toorPIA
Identical results across seeds
The reference map, normal region, and thresholds stay fixed — a map you can operate as a long-term monitoring system.
Keep both the distance and the kind
of an outlier on the map
A dataset mixes three kinds of outliers — six points in total, a near-duplicate pair per kind — into the normal clusters, and measures how faithfully outlier-involving distances survive the trip to 2D. toorPIA keeps same-kind outlier pairs co-directional (within 10°) and separates the three kinds into distinct locations — preserving both how far off a point is and what kind of deviation it is.
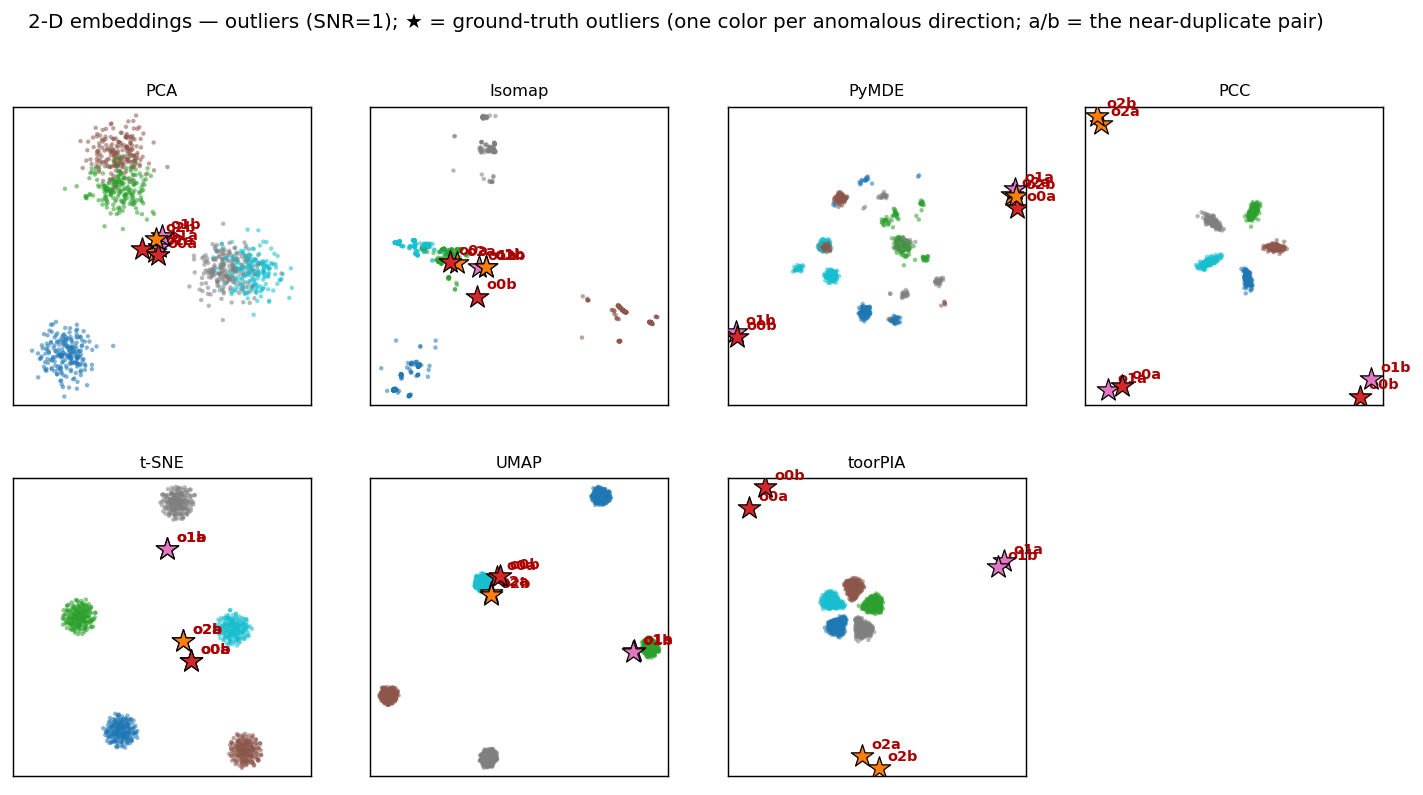
★ = ground-truth outliers (color = kind of anomaly; a/b = the near-duplicate pair). In PCA and Isomap the outliers sink into the clusters; in toorPIA the three kinds separate in different directions with each a/b pair adjacent.
Shepard ρ restricted to outlier pairs (higher = more faithful)
Rank correlation between high-dimensional and 2D distances, restricted to outlier-involving pairs (outliers dataset, SNR=1)
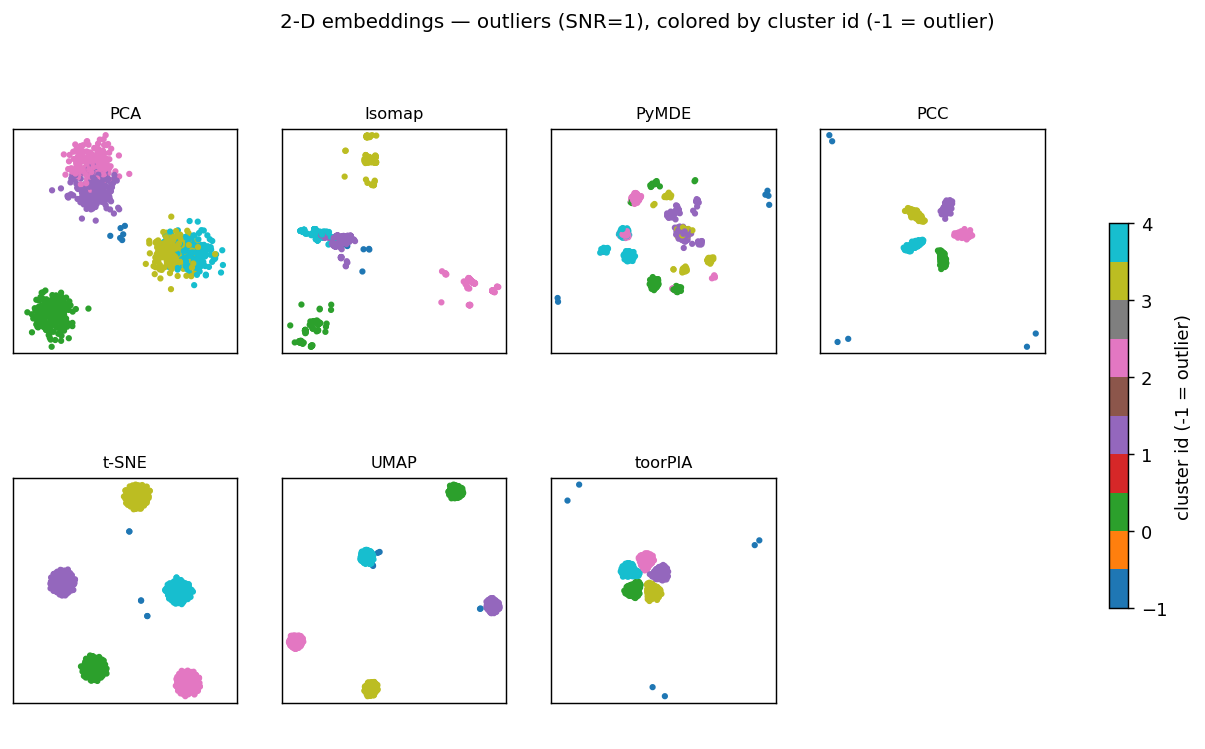
The full picture, colored by cluster id. toorPIA keeps the mutual layout of the five clusters while pushing the outliers (blue) outward.
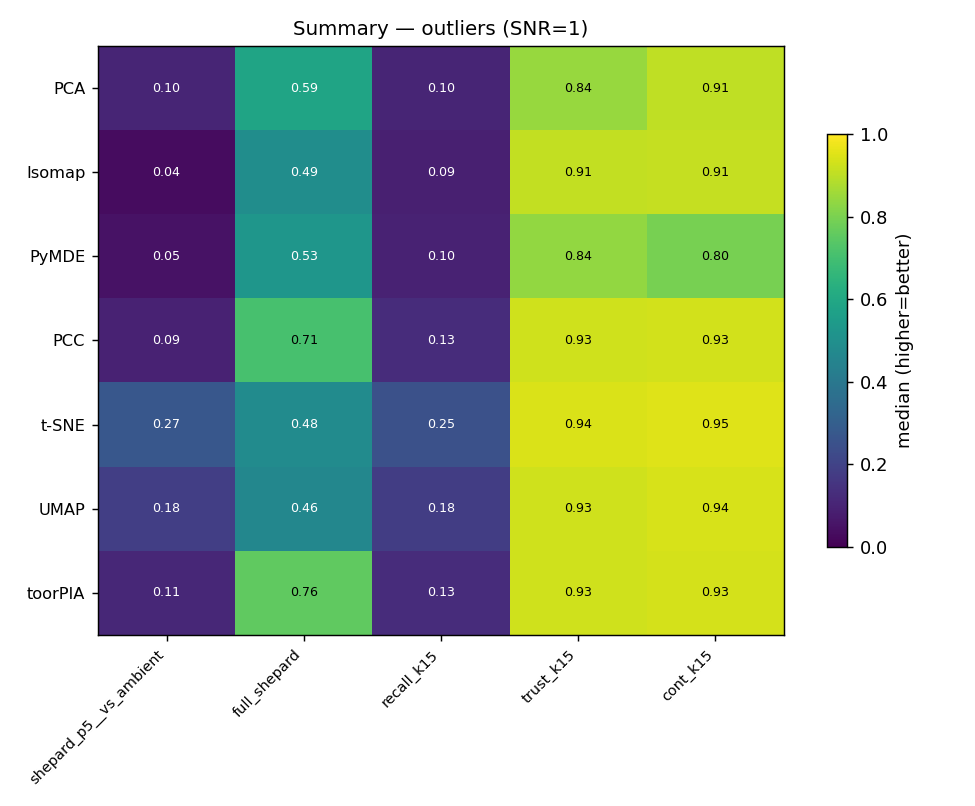
Metric summary. On full-pair Shepard ρ, toorPIA leads at 0.76. On neighborhood-preservation metrics (recall / trustworthiness), t-SNE and UMAP score higher — see “Methods & Limits” below.
When 95% of the data is normal,
don't crush the other 5%
In real monitoring data, the states you care about — anomalies, transients, rare events — are a small minority. Worse, nobody tells you in advance that the minority exists. Tested on a 95% majority vs. 5% minority split, toorPIA keeps the minority's internal structure visible while separating it from the majority, and achieves the best overall distance fidelity (full Shepard ρ = 0.809).
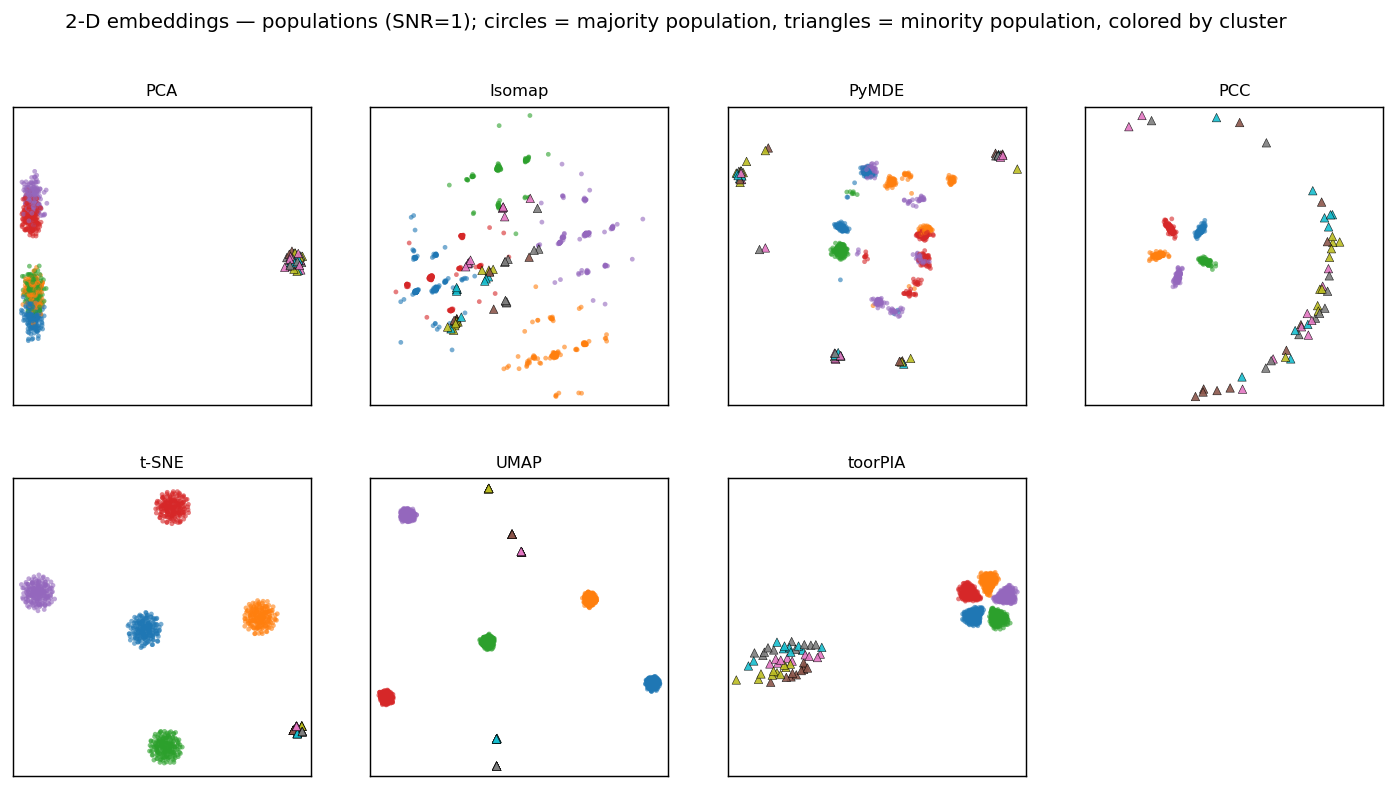
○ = majority, △ = minority. PCA collapses the majority clusters onto each other; t-SNE and UMAP compress the minority into dots. toorPIA preserves both the five-cluster structure of the majority and the internal spread of the minority.
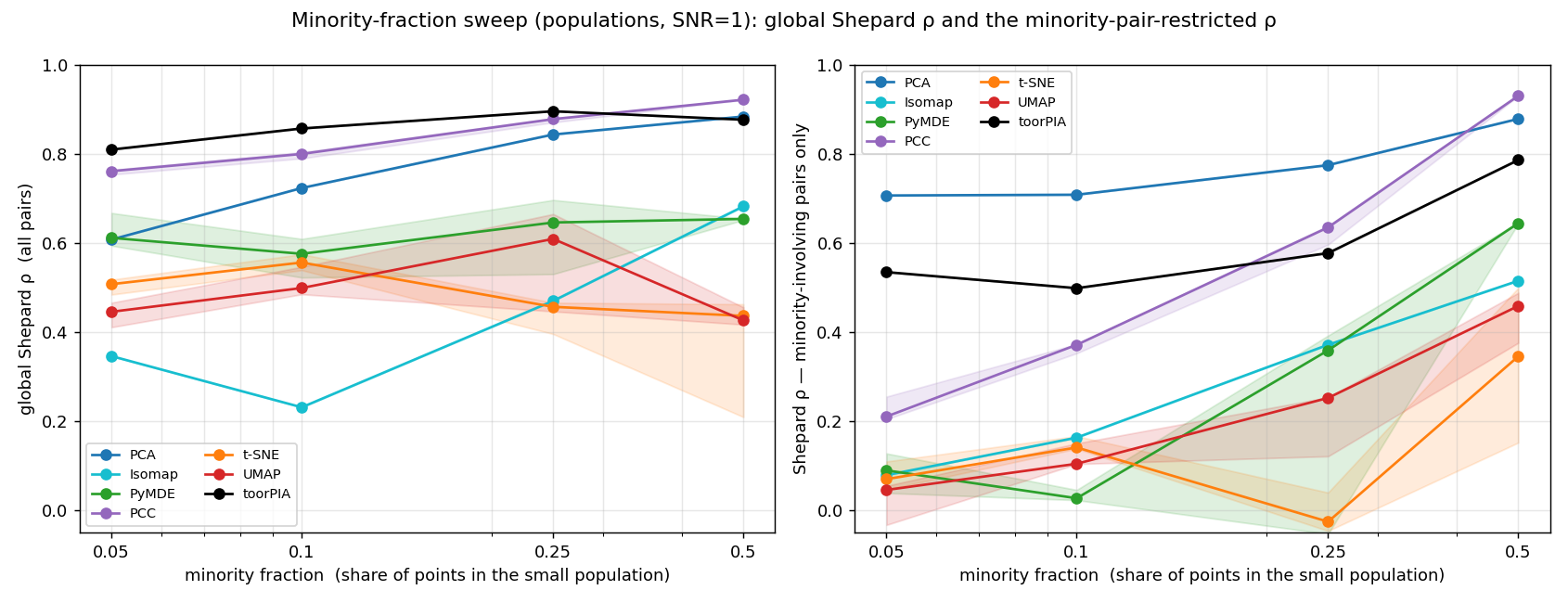
Sweeping the minority share from 50% down to 5%
We lowered the minority fraction step by step to see where each method breaks down. On full-pair Shepard ρ (left), toorPIA stays at the top even at the most imbalanced 5% setting.
On ρ restricted to minority-involving pairs (right), PCA also scores high — but PCA collapses the majority clusters onto each other (see the gallery above), so its map is unusable in practice. Reporting multiple perspectives rather than a single score is a design principle of this benchmark.
What this measures — and what it doesn't
The benchmark measures how faithfully high-dimensional distance structure is carried into 2D, on five synthetic datasets with known ground-truth geometry (non-uniform density, dense clusters, continuous transition, outliers, imbalanced populations). The core metric, distance-band Shepard ρ, takes the rank correlation between high-dimensional and 2D distances within distance-percentile bands, and is computed directly on all pairwise distances, independently of any method.
On k-nearest-neighbor preservation metrics such as recall@k, t-SNE and UMAP rank higher. That reflects a difference in what each method optimizes for, and the benchmark deliberately reports multiple metrics on the premise that no single number tells the whole story. If reproducing local neighborhoods is the goal, neighbor-based methods are the right tool; if the goal is a monitoring map that preserves distances, directions, and minority structure, toorPIA is — that is the takeaway.
* All results are on synthetic data; applicability to real data must be validated per project. The repository is maintained by the vendor of toorPIA, and transparency safeguards (hypotheses documented before results, all output coordinates published, no winner claimed on overlapping confidence intervals) are in place with that in mind. For the experimental conditions, metric definitions, and complete numbers, see the README and REPORT on GitHub.
Every number here can be recomputed on your machine.
The code, the data generators, and every method's output coordinates are published under the MIT License. For questions about applying toorPIA to precursor monitoring, feel free to contact us.