AIの“頭の中”を、
地図にする。
AIの態度が、揺れはじめるところ。
大規模言語モデル(LLM)が答えを生み出すとき、その内部では 数千次元(モデルによっては5,000次元を超える)の 「隠れ状態(hidden state)」が刻々と動いています。 その高次元の動きを toorPIA で2次元地図に落とすと、 AIが“立場”をどう形づくり、どこで迷うのかが、はじめて目に見えてきました。
数千次元
内部状態 (hidden state)
2D
toorPIAで可視化
0.91
立場の連続性 (Spearman)
AIの良し悪しは、いまも「出力された文章」を読んで採点しています。 でも、モデルが内部で迷わず確信していたのか、 立場を連続的に表せていたのかは、文章だけからは見えません。 私たちは toorPIA で内部状態そのものを可視化し、 テキストには現れない“振る舞いの質”を測る試みを進めています。
立場は、層を深めるごとに
“像を結ぶ”
同じ問い「原発は正しいエネルギー政策か?」に、Qwen3-4B が 反対・賛成の立場で答えるとき、 浅い層ではどちらもぼやけた一つの塊。 層が深くなるにつれ青と赤がくっきり分かれ、 文脈を取り込んだ語が連なって鎖状(フィラメント)構造へと織り上がっていきます。
全36層の toorPIA 地図を連続再生。下のリボンが「いま見ている層」、発光する線が各立場の代表的な回答。
賛成と反対は、“白黒”ではなく
“連続グラデーション”
立場を強い反対→反対→中立→賛成→強い賛成の5段で各40回(計200回)答えさせ、 全トークンの内部状態を1枚の地図に。すると立場は離散的なYes/Noではなく、 反対↔賛成の連続した軸として内部に刻まれていました (立場軸への射影との相関 Spearman = 0.91)。
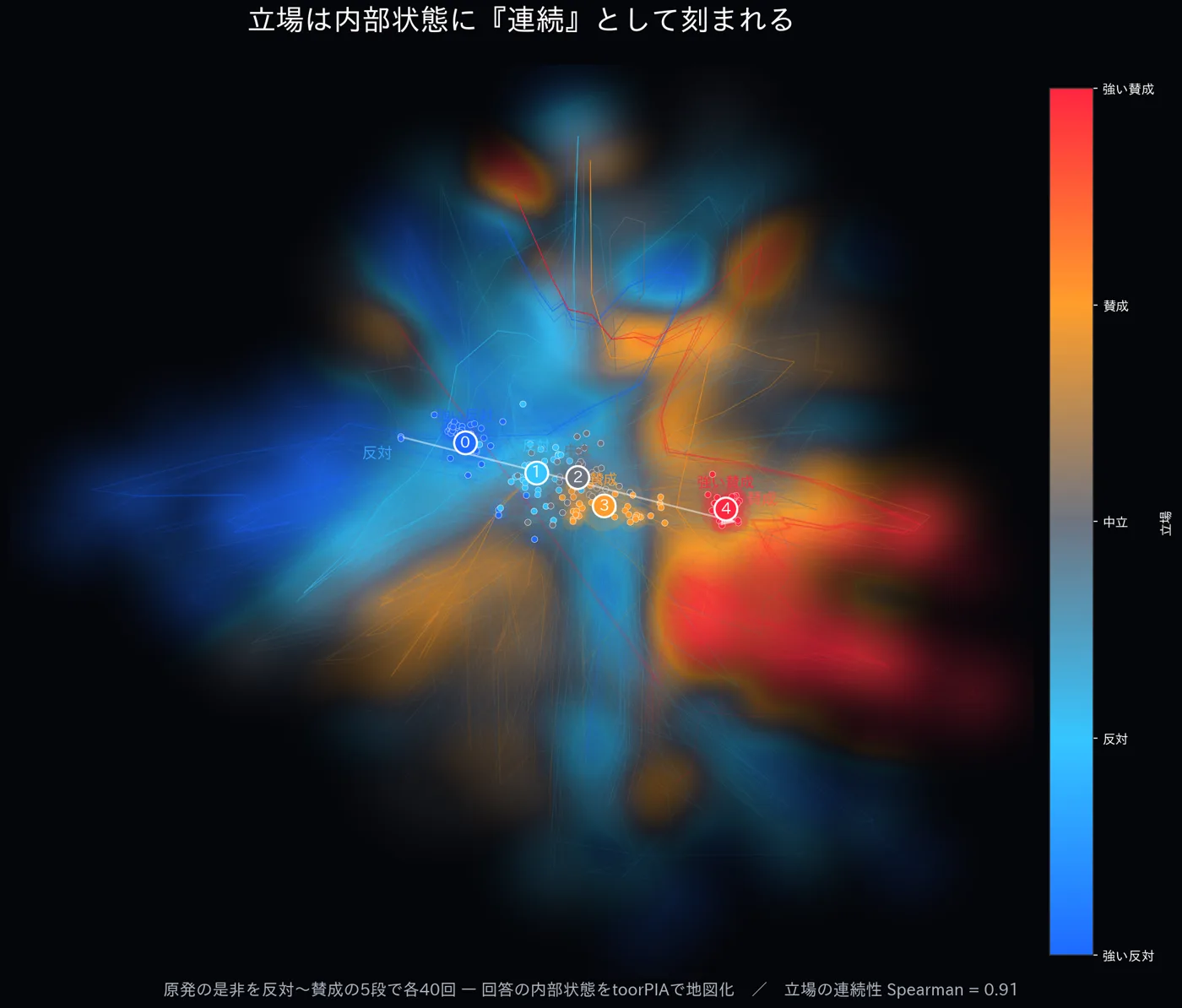
立場 s を反対→賛成へスイープすると、その立場に対応する領域が連続的に発光して移動します(左)。 5段の重心も反対(青)→中立→賛成(赤)へ滑らかに並びます(右)。
いちばん揺れるのは、“中立”
同じ問いを同じ温度で何度も答えさせると、内部の軌跡は毎回少しずつ違います=モデルの“揺らぎ”。 各立場の代表回答(芯)のまわりの広がりを測ると―― 中立は、すべての層で最も大きく揺れていました (強い反対・強い賛成の約 2.5〜3.5倍)。 確信した立場ほど内部は締まり、中立ほど内部が揺れる。 これは正答率やテキストでは見えない、“決断性・確信度”の手がかりです。
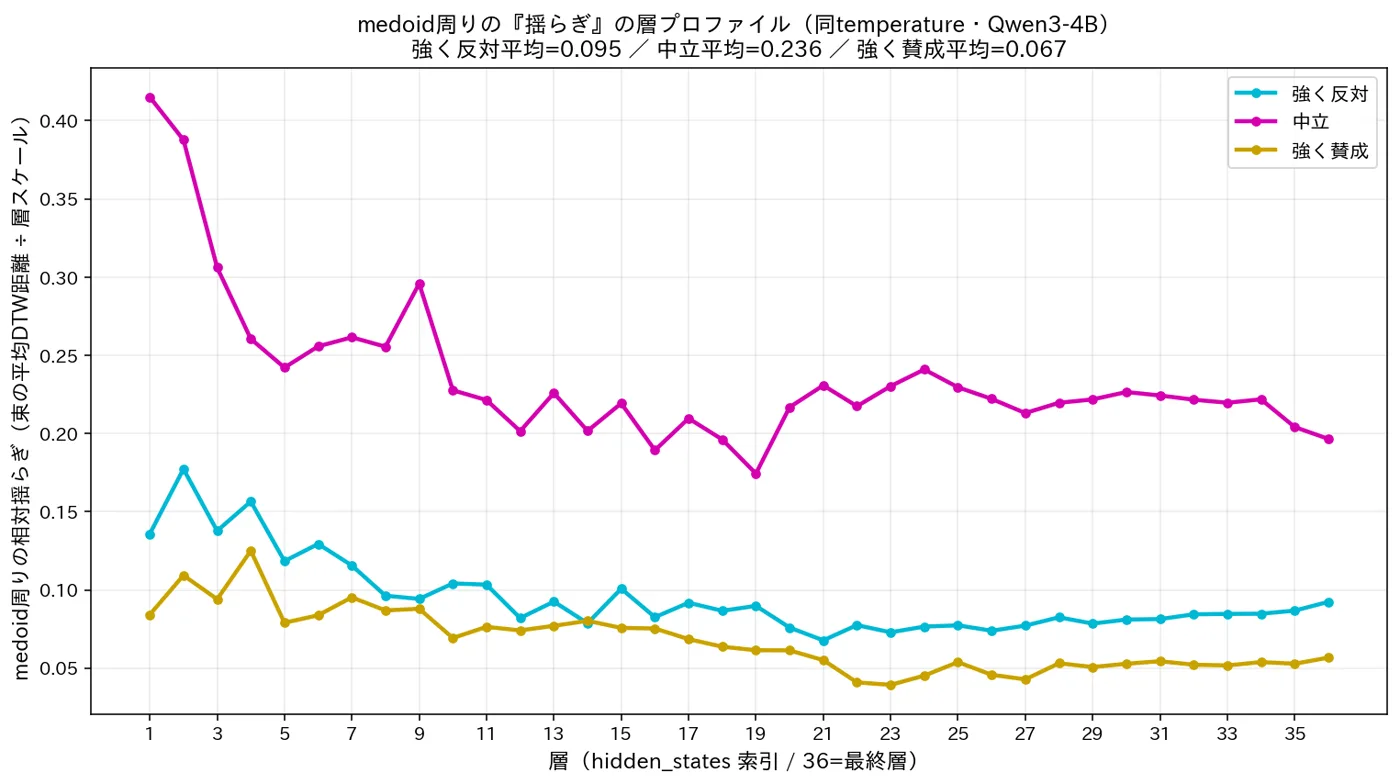
マゼンタ(中立)の曲線が、全層を通じてシアン(強い反対)・黄(強い賛成)よりはっきり上にあります。 温度を全条件でそろえているため、この差は温度ではなくモデルの内部状態そのものに由来します。
テキストを読まずに、AIの“質”を測る
ベンチマークの正答率は「出力テキスト」の採点であり、別のAIや人手の判定に頼りがちです。 私たちが目指すのは、外部の判定器に依らず、内部状態そのものから 一貫性・確信度・立場の連続性を再現可能に定量すること。 その出発点が、toorPIA による高次元データの可視化です。 粗視化した内部の「軌跡」を、高分子物理の記述子(持続長など)のような 物理由来の言語で語る――そんな科学的な評価軸への一歩を試みています。
※ 本ページは研究の“さわり”の紹介です。ここで示した観察は探索的なものを含み、 その有効性は今後さらに定量的に検証していきます。
この続きは、直接お話しします。
LLMの内部可視化・品質評価への応用、デモ、共同研究のご相談など、お気軽にお問い合わせください。 詳細は私たちが直接ご説明に伺います。
図・動画は toorPIA の出力を含みます。© 2026 toor Inc. / MIT License